How to analyze cluster sample Hawkes Bay
Conduct and Interpret a Cluster Analysis Statistics SAS/STAT Software Cluster Analysis. The purpose of cluster analysis is to place objects into groups, or clusters, suggested by the data, not defined a priori, such that objects in a given cluster tend to be similar to each other in some sense, and objects in different clusters tend to be dissimilar.
DBSCAN.Analyse Cluster C# (CSharp) Code Examples
On the Nature and Analysis of Clustered Data. Data starts as one combined cluster. The cluster splits into two distinct parts, according to some degree of similarity. Clusters split into two again and again until the clusters only contain a single data point. Divisive clustering is very rarely used. Downsides. Hierarchical clustering can easily lead to dendrograms that are just plain wrong., Cluster Sampling: Definition. Cluster sampling is defined as a sampling method where multiple clusters of people are created from a population where they are indicative of homogeneous characteristics and have an equal chance of being a part of the sample..
The TwoStep Cluster Analysis procedure is an exploratory tool designed to reveal natural groupings (or clusters) within a dataset that would otherwise not be apparent. The algorithm employed by this procedure has several desirable features that differentiate it from traditional clustering techniques: C# (CSharp) Cluster DBSCAN.Analyse - 6 examples found. These are the top rated real world C# (CSharp) examples of Cluster.DBSCAN.Analyse extracted from open source projects. You can rate examples to help us improve the quality of examples.
Cluster Analysis for Dummies 1. Data Analysis Course Cluster Analysis Venkat Reddy 2. Contents • What is the need of Segmentation • Introduction to Segmentation & Cluster analysis • Applications of Cluster Analysis • Types of Clusters • K-Means clustering DataAnalysisCourse VenkatReddy 2 Cluster analysis. A cluster analysis allows you summarise a dataset by grouping similar observations together into clusters. Observations are judged to be similar if they have similar values for a number of variables (i.e. a short Euclidean distance between them).
Cluster analysis has been used to cluster stocks into sectors. Petroleum geology Cluster analysis is used to reconstruct missing bottom hole core data or missing log curves in order to evaluate reservoir properties. Physical geography The clustering of chemical properties in different sample … 03/12/2015 · Cluster analysis is an important tool related to analyzing big data or working in data science field. Deep Learning: https://goo.gl/5VtSuC Image Analysis & Classification: https://goo.gl/Md3fMi
among clusters can no longer be estimated. For example, fixed effects regression models can be used to analyze multicenter trials, but not cluster-randomized trials. Fixed effects regression models can only estimate effects of covariates that vary within clusters. … Some publications using cluster analysis mention O=2 m, where m is the number of attributes and O is the number of objects (or observations), as a rule of thumb for the size of the dataset.
How to cluster your customer data — with R code examples Clustering customer data helps find hidden patterns in your data by grouping similar things for you. For example you can create customer personas based on activity and tailor offerings to those groups. cluster— Introduction to cluster-analysis commands 5 Data transformations (such as standardization of variables) and the variables selected for use in clustering can also greatly affect the groupings that are discovered. These and other cluster-analysis data issues are covered inMilligan and Cooper(1988) andSchaffer and Green(1996) and in many
# import hierarchical clustering libraries import scipy.cluster.hierarchy as sch from sklearn.cluster import AgglomerativeClustering. Now, let’s create our dendrogram (which I’ve already shown you above), determine how many clusters we want, and save the data points from those clusters to chart them out. How to Analyze Survey Data. A good analysis of survey data from a cluster sample includes seven steps: Estimate a population parameter. Compute sample variance within each cluster (for two-stage cluster …
Chapter 8 Cluster Analysis SPSS - Cluster Analysis How to get there: Analyze Classify … Hierarchical Cluster… This procedure attempts to identify relatively homogeneous groups of cases (or variables) based on selected characteristics. For example: cluster television shows into homogeneous groups based on viewer characteristics. In hierarchical clustering, an algorithm is used that Some publications using cluster analysis mention O=2 m, where m is the number of attributes and O is the number of objects (or observations), as a rule of thumb for the size of the dataset.
C# (CSharp) Cluster DBSCAN.Analyse - 6 examples found. These are the top rated real world C# (CSharp) examples of Cluster.DBSCAN.Analyse extracted from open source projects. You can rate examples to help us improve the quality of examples. Use HDInsight Spark cluster to analyze data in Data Lake Storage Gen1. 06/13/2019; 4 minutes to read +4; In this article. In this article, you use Jupyter Notebook available with HDInsight Spark clusters to run a job that reads data from a Data Lake Storage account.
cluster— Introduction to cluster-analysis commands 5 Data transformations (such as standardization of variables) and the variables selected for use in clustering can also greatly affect the groupings that are discovered. These and other cluster-analysis data issues are covered inMilligan and Cooper(1988) andSchaffer and Green(1996) and in many Cluster Analysis depends on, among other things, the size of the data file. Methods commonly used for small data sets are impractical for data files with thousands of cases. SPSS has three different procedures that can be used to cluster data: hierarchical cluster analysis, k-means cluster, and two-step cluster. They are all described in this
among clusters can no longer be estimated. For example, fixed effects regression models can be used to analyze multicenter trials, but not cluster-randomized trials. Fixed effects regression models can only estimate effects of covariates that vary within clusters. … After looking around I cannot find anything which might suggest a suitable sample size or even that sample size is not important and I'm pretty sure power analyses don't apply for cluster analysis. Is there anything I can report to show my sample size is sufficient (or not if the case may be)? I am using R to analyse the data.
Analyze website logs with Python libraries in Spark

Chapter 8 SPSS Cluster Analyses. 06/12/2012В В· Cluster analysis is descriptive, atheoretical, and noninferential. Cluster analysis has no statistical basis upon which to draw inferences from a sample to a population, and many contend that it is only an exploratory technique. Nothing guarantees unique solutions, because the cluster membership for any number of solutions is dependent upon, To conduct a cluster sample, the researcher first selects groups or clusters and then from each cluster, selects the individual subjects either by simple random sampling or systematic random sampling. Or, if the cluster is small enough, the researcher may choose to include the entire cluster in the final sample rather than a subset of it..
Interpret the key results for Cluster K-Means Minitab

Interpret the key results for Cluster K-Means Minitab. SAS/STAT Software Cluster Analysis. The purpose of cluster analysis is to place objects into groups, or clusters, suggested by the data, not defined a priori, such that objects in a given cluster tend to be similar to each other in some sense, and objects in different clusters tend to be dissimilar. https://simple.wikipedia.org/wiki/Cluster_analysis # import hierarchical clustering libraries import scipy.cluster.hierarchy as sch from sklearn.cluster import AgglomerativeClustering. Now, let’s create our dendrogram (which I’ve already shown you above), determine how many clusters we want, and save the data points from those clusters to chart them out..
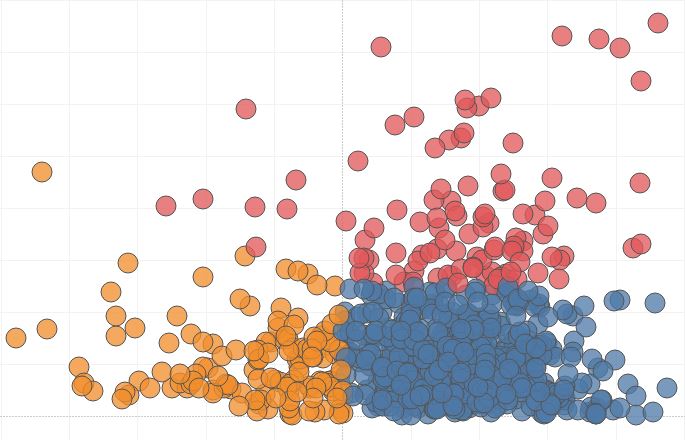
Cluster random samples cannot have crossover. Cluster random samples must include all members of a population. Let's start with the rule that cluster random samples cannot have crossover. In other How to Answer Business Questions Using Cluster Analysis in R. Greg Marsh . Follow. Sep 14, 2016 В· 4 min read. Aptitive has partnered with a variety of companies to build out extensive platforms for analyzing their data. The tremendous value in creating a business intelligence environment is to allow users to answer much more complex and interesting questions. In addition to visualizing the
Cluster Analysis depends on, among other things, the size of the data file. Methods commonly used for small data sets are impractical for data files with thousands of cases. SPSS has three different procedures that can be used to cluster data: hierarchical cluster analysis, k-means cluster, and two-step cluster. They are all described in this 23/02/2018В В· If you were asked to cluster your standard errors by country, then, yes the -vce(cluster country)- option (not command) is the way to do that and the syntax you show for that is correct. If you are not sure why you were asked to do this, you should probably ask the person who told you to do it in the first place. It's really a matter about the
In part 4 of this series, I talked about how to generate the cluster debug log for digging deeper on what caused the WSFC or the workloads running on top of it to go offline. I also walked you thru the process of getting started with reading the logs. Analyzing the cluster debug log is more of a root cause analysis (RCA) activity rather than a How to Answer Business Questions Using Cluster Analysis in R. Greg Marsh . Follow. Sep 14, 2016 В· 4 min read. Aptitive has partnered with a variety of companies to build out extensive platforms for analyzing their data. The tremendous value in creating a business intelligence environment is to allow users to answer much more complex and interesting questions. In addition to visualizing the
Cluster Analysis depends on, among other things, the size of the data file. Methods commonly used for small data sets are impractical for data files with thousands of cases. SPSS has three different procedures that can be used to cluster data: hierarchical cluster analysis, k-means cluster, and two-step cluster. They are all described in this How to Answer Business Questions Using Cluster Analysis in R. Greg Marsh . Follow. Sep 14, 2016 В· 4 min read. Aptitive has partnered with a variety of companies to build out extensive platforms for analyzing their data. The tremendous value in creating a business intelligence environment is to allow users to answer much more complex and interesting questions. In addition to visualizing the
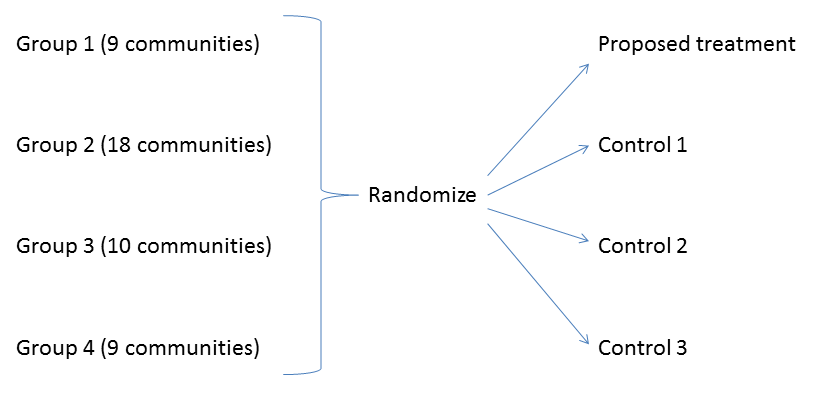
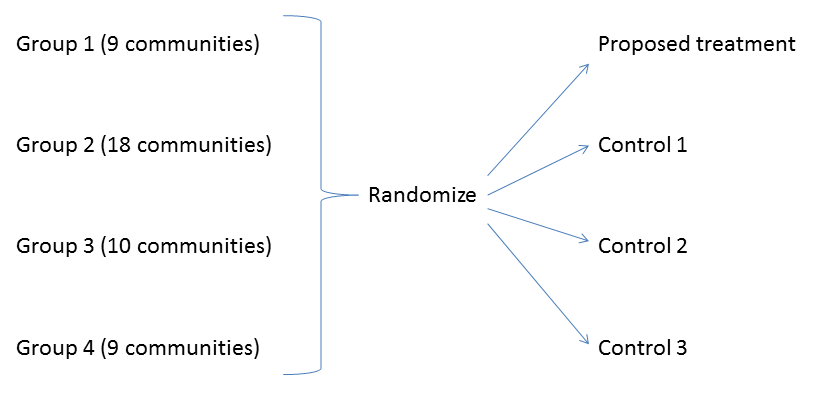
Cluster Sampling: Definition. Cluster sampling is defined as a sampling method where multiple clusters of people are created from a population where they are indicative of homogeneous characteristics and have an equal chance of being a part of the sample. Five clusters with a total of 32 municipalities are randomly selected. The results from the regression analysis in which clusters are used in the sample design are compared to the results of a regression analysis that ignores the clusters. The linear relationship …
After looking around I cannot find anything which might suggest a suitable sample size or even that sample size is not important and I'm pretty sure power analyses don't apply for cluster analysis. Is there anything I can report to show my sample size is sufficient (or not if the case may be)? I am using R to analyse the data. In part 4 of this series, I talked about how to generate the cluster debug log for digging deeper on what caused the WSFC or the workloads running on top of it to go offline. I also walked you thru the process of getting started with reading the logs. Analyzing the cluster debug log is more of a root cause analysis (RCA) activity rather than a
How to cluster your customer data — with R code examples Clustering customer data helps find hidden patterns in your data by grouping similar things for you. For example you can create customer personas based on activity and tailor offerings to those groups. Some publications using cluster analysis mention O=2 m, where m is the number of attributes and O is the number of objects (or observations), as a rule of thumb for the size of the dataset.
Analyzing Tables, Indexes, and Clusters. You analyze a schema object (table, index, or cluster) to: Collect and manage statistics for it. Verify the validity of its storage format I have data from a cluster randomized trial, that is, each subject in the same cluster has received the same treatment. Do chi square test and t-test need some adjustments? More precisely, which analysis have I to carry out in Spss to compare frequency in contingency tables and to compare means for quantitative variables?
Cluster random samples cannot have crossover. Cluster random samples must include all members of a population. Let's start with the rule that cluster random samples cannot have crossover. In other Complete the following steps to interpret a cluster k-means analysis. Key output includes the observations and the variability measures for the clusters in the final partition.
Performing and Interpreting Cluster Analysis For the hierarchial clustering methods, the dendogram is the main graphical tool for getting insight into a cluster solution. When you use hclust or agnes to perform a cluster analysis, you can see the dendogram by passing the result of the clustering to the plot function. 03/12/2015В В· Cluster analysis is an important tool related to analyzing big data or working in data science field. Deep Learning: https://goo.gl/5VtSuC Image Analysis & Classification: https://goo.gl/Md3fMi
The Cluster Analysis in SPSS. Our research question for this example cluster analysis is as follows: What homogenous clusters of students emerge based on standardized test scores in mathematics, reading, and writing? In SPSS Cluster Analyses can be found in Analyze/Classify…. 31/01/2016 · A step by step guide of how to run k-means clustering in Excel. Please note that more information on cluster analysis and a free Excel template is available
What is the minimum sample size to conduct a cluster analysis?
Cluster Analysis for Dummies. 06/12/2012В В· Cluster analysis is descriptive, atheoretical, and noninferential. Cluster analysis has no statistical basis upon which to draw inferences from a sample to a population, and many contend that it is only an exploratory technique. Nothing guarantees unique solutions, because the cluster membership for any number of solutions is dependent upon, Analyzing Tables, Indexes, and Clusters. You analyze a schema object (table, index, or cluster) to: Collect and manage statistics for it. Verify the validity of its storage format.
An Introduction to Clustering Algorithms in Python
Cluster Analysis norusis.com. cluster— Introduction to cluster-analysis commands 5 Data transformations (such as standardization of variables) and the variables selected for use in clustering can also greatly affect the groupings that are discovered. These and other cluster-analysis data issues are covered inMilligan and Cooper(1988) andSchaffer and Green(1996) and in many, ANALYZE. Purpose. Use the ANALYZE statement to collect statistics, for example, to: Collect or delete statistics about an index or index partition, table or table partition, index-organized table, cluster, or ….
More precisely, if one plots the percentage of variance explained by the clusters against the number of clusters, the first clusters will add much information (explain a lot of variance), but at some point the marginal gain will drop, giving an angle in the graph. The number of clusters is chosen at this point, hence the “elbow criterion”. The
Cluster random samples cannot have crossover. Cluster random samples must include all members of a population. Let's start with the rule that cluster random samples cannot have crossover. In other Cluster Sampling: Definition. Cluster sampling is defined as a sampling method where multiple clusters of people are created from a population where they are indicative of homogeneous characteristics and have an equal chance of being a part of the sample.
After looking around I cannot find anything which might suggest a suitable sample size or even that sample size is not important and I'm pretty sure power analyses don't apply for cluster analysis. Is there anything I can report to show my sample size is sufficient (or not if the case may be)? I am using R to analyse the data. to a sample of university students, and discusses the quantitative results. In the last section we analyze the results of ClA procedures in order to give meaning to quantitative results and compare them with previous results reported in the literature, by pointing out the new insights resulting from the application of such ClA methods. II
A compensatory increase in sample size is required to maintain power in a cluster RCT, and the degree of similarity within clusters should also be assessed. Intra-cluster correlation coefficient (ICC) The intra-cluster correlation coefficient (ICC) is a measure of the relatedness, or similarity, of clustered data. It is depicted by the Greek 03/12/2015В В· Cluster analysis is an important tool related to analyzing big data or working in data science field. Deep Learning: https://goo.gl/5VtSuC Image Analysis & Classification: https://goo.gl/Md3fMi
26/03/2004В В· Computation of the effective sample size is important, as it avoids costly sample size errors caused by underpowered studies. Examples in the Killip et al article show how the intracluster correlation, number of observations within a cluster, and number of clusters are all interrelated in estimating sample size and power for clustered data. After looking around I cannot find anything which might suggest a suitable sample size or even that sample size is not important and I'm pretty sure power analyses don't apply for cluster analysis. Is there anything I can report to show my sample size is sufficient (or not if the case may be)? I am using R to analyse the data.
Five clusters with a total of 32 municipalities are randomly selected. The results from the regression analysis in which clusters are used in the sample design are compared to the results of a regression analysis that ignores the clusters. The linear relationship … The TwoStep Cluster Analysis procedure is an exploratory tool designed to reveal natural groupings (or clusters) within a dataset that would otherwise not be apparent. The algorithm employed by this procedure has several desirable features that differentiate it from traditional clustering techniques:
Example. Example 1: Apply the second version of the K-means clustering algorithm to the data in range B3:C13 of Figure 1 with k = 2. Figure 1 – K-means cluster analysis (part 1) The data consists of 10 data elements which can be viewed as two-dimensional points (see Figure 3 for a graphical representation). Since there are two clusters, we ANALYZE. Purpose. Use the ANALYZE statement to collect statistics, for example, to: Collect or delete statistics about an index or index partition, table or table partition, index-organized table, cluster, or …
I have data from a cluster randomized trial, that is, each subject in the same cluster has received the same treatment. Do chi square test and t-test need some adjustments? More precisely, which analysis have I to carry out in Spss to compare frequency in contingency tables and to compare means for quantitative variables? SAS/STAT Software Cluster Analysis. The purpose of cluster analysis is to place objects into groups, or clusters, suggested by the data, not defined a priori, such that objects in a given cluster tend to be similar to each other in some sense, and objects in different clusters tend to be dissimilar.
Analyze website logs using a custom Python library with Apache Spark cluster on HDInsight. 11/28/2017; 7 minutes to read; In this article. This notebook demonstrates how to analyze log data using a custom library with Apache Spark on HDInsight. In our example, the objective was to identify customer segments with similar buying behavior. Hence, clustering was performed using variables that represent the customer buying patterns. Cluster analysis can be used to discover structures in data without providing an explanation or interpretation. In other words, cluster analysis simply
Five clusters with a total of 32 municipalities are randomly selected. The results from the regression analysis in which clusters are used in the sample design are compared to the results of a regression analysis that ignores the clusters. The linear relationship … Use HDInsight Spark cluster to analyze data in Data Lake Storage Gen1. 06/13/2019; 4 minutes to read +4; In this article. In this article, you use Jupyter Notebook available with HDInsight Spark clusters to run a job that reads data from a Data Lake Storage account.
# import hierarchical clustering libraries import scipy.cluster.hierarchy as sch from sklearn.cluster import AgglomerativeClustering. Now, let’s create our dendrogram (which I’ve already shown you above), determine how many clusters we want, and save the data points from those clusters to chart them out. Data starts as one combined cluster. The cluster splits into two distinct parts, according to some degree of similarity. Clusters split into two again and again until the clusters only contain a single data point. Divisive clustering is very rarely used. Downsides. Hierarchical clustering can easily lead to dendrograms that are just plain wrong.
Making Sense of the Windows Server Failover Cluster Debug
r Sample size for cluster analysis - Cross Validated. # import hierarchical clustering libraries import scipy.cluster.hierarchy as sch from sklearn.cluster import AgglomerativeClustering. Now, let’s create our dendrogram (which I’ve already shown you above), determine how many clusters we want, and save the data points from those clusters to chart them out., What is Cluster Sampling? Cluster sampling refers to a sampling method that has the following properties. The population is divided into N groups, called clusters. The researcher randomly selects n clusters to include in the sample. The number of observations within each cluster M i is known, and M = M 1 + M 2 + M 3 + + M N-1 + M N..
Introduction to Cluster Analysis with R an Example - YouTube. SAS/STAT Software Cluster Analysis. The purpose of cluster analysis is to place objects into groups, or clusters, suggested by the data, not defined a priori, such that objects in a given cluster tend to be similar to each other in some sense, and objects in different clusters tend to be dissimilar., 06/12/2012В В· Cluster analysis is descriptive, atheoretical, and noninferential. Cluster analysis has no statistical basis upon which to draw inferences from a sample to a population, and many contend that it is only an exploratory technique. Nothing guarantees unique solutions, because the cluster membership for any number of solutions is dependent upon.
Cluster Analysis norusis.com
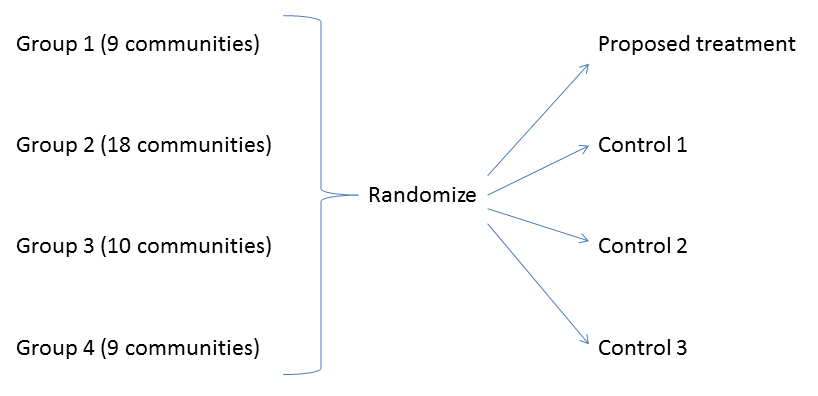
Cluster Sample in Sociology Research ThoughtCo. More precisely, if one plots the percentage of variance explained by the clusters against the number of clusters, the first clusters will add much information (explain a lot of variance), but at some point the marginal gain will drop, giving an angle in the graph. The number of clusters is chosen at this point, hence the “elbow criterion”. https://en.m.wikipedia.org/wiki/Cluster_randomized_trial The TwoStep Cluster Analysis procedure is an exploratory tool designed to reveal natural groupings (or clusters) within a dataset that would otherwise not be apparent. The algorithm employed by this procedure has several desirable features that differentiate it from traditional clustering techniques:.

Cluster random samples cannot have crossover. Cluster random samples must include all members of a population. Let's start with the rule that cluster random samples cannot have crossover. In other ANALYZE. Purpose. Use the ANALYZE statement to collect statistics, for example, to: Collect or delete statistics about an index or index partition, table or table partition, index-organized table, cluster, or …
How do I analyze survey data with a one-stage cluster design? R FAQ As a statistical programming language, R allows users to access precise statistics instead of simply printing a … The
Complete the following steps to interpret a cluster k-means analysis. Key output includes the observations and the variability measures for the clusters in the final partition. The Cluster Analysis in SPSS. Our research question for this example cluster analysis is as follows: What homogenous clusters of students emerge based on standardized test scores in mathematics, reading, and writing? In SPSS Cluster Analyses can be found in Analyze/Classify….
Example. Example 1: Apply the second version of the K-means clustering algorithm to the data in range B3:C13 of Figure 1 with k = 2. Figure 1 – K-means cluster analysis (part 1) The data consists of 10 data elements which can be viewed as two-dimensional points (see Figure 3 for a graphical representation). Since there are two clusters, we Performing and Interpreting Cluster Analysis For the hierarchial clustering methods, the dendogram is the main graphical tool for getting insight into a cluster solution. When you use hclust or agnes to perform a cluster analysis, you can see the dendogram by passing the result of the clustering to the plot function.
Cluster analysis. A cluster analysis allows you summarise a dataset by grouping similar observations together into clusters. Observations are judged to be similar if they have similar values for a number of variables (i.e. a short Euclidean distance between them). Cluster analysis has been used to cluster stocks into sectors. Petroleum geology Cluster analysis is used to reconstruct missing bottom hole core data or missing log curves in order to evaluate reservoir properties. Physical geography The clustering of chemical properties in different sample …
# import hierarchical clustering libraries import scipy.cluster.hierarchy as sch from sklearn.cluster import AgglomerativeClustering. Now, let’s create our dendrogram (which I’ve already shown you above), determine how many clusters we want, and save the data points from those clusters to chart them out. How to cluster your customer data — with R code examples Clustering customer data helps find hidden patterns in your data by grouping similar things for you. For example you can create customer personas based on activity and tailor offerings to those groups.
Five clusters with a total of 32 municipalities are randomly selected. The results from the regression analysis in which clusters are used in the sample design are compared to the results of a regression analysis that ignores the clusters. The linear relationship … to a sample of university students, and discusses the quantitative results. In the last section we analyze the results of ClA procedures in order to give meaning to quantitative results and compare them with previous results reported in the literature, by pointing out the new insights resulting from the application of such ClA methods. II
In part 4 of this series, I talked about how to generate the cluster debug log for digging deeper on what caused the WSFC or the workloads running on top of it to go offline. I also walked you thru the process of getting started with reading the logs. Analyzing the cluster debug log is more of a root cause analysis (RCA) activity rather than a Cluster Analysis depends on, among other things, the size of the data file. Methods commonly used for small data sets are impractical for data files with thousands of cases. SPSS has three different procedures that can be used to cluster data: hierarchical cluster analysis, k-means cluster, and two-step cluster. They are all described in this
Cluster Analysis for Dummies 1. Data Analysis Course Cluster Analysis Venkat Reddy 2. Contents • What is the need of Segmentation • Introduction to Segmentation & Cluster analysis • Applications of Cluster Analysis • Types of Clusters • K-Means clustering DataAnalysisCourse VenkatReddy 2 Cluster Sampling: Definition. Cluster sampling is defined as a sampling method where multiple clusters of people are created from a population where they are indicative of homogeneous characteristics and have an equal chance of being a part of the sample.
How do I analyze survey data with a one-stage cluster design? R FAQ As a statistical programming language, R allows users to access precise statistics instead of simply printing a … Cluster Analysis depends on, among other things, the size of the data file. Methods commonly used for small data sets are impractical for data files with thousands of cases. SPSS has three different procedures that can be used to cluster data: hierarchical cluster analysis, k-means cluster, and two-step cluster. They are all described in this
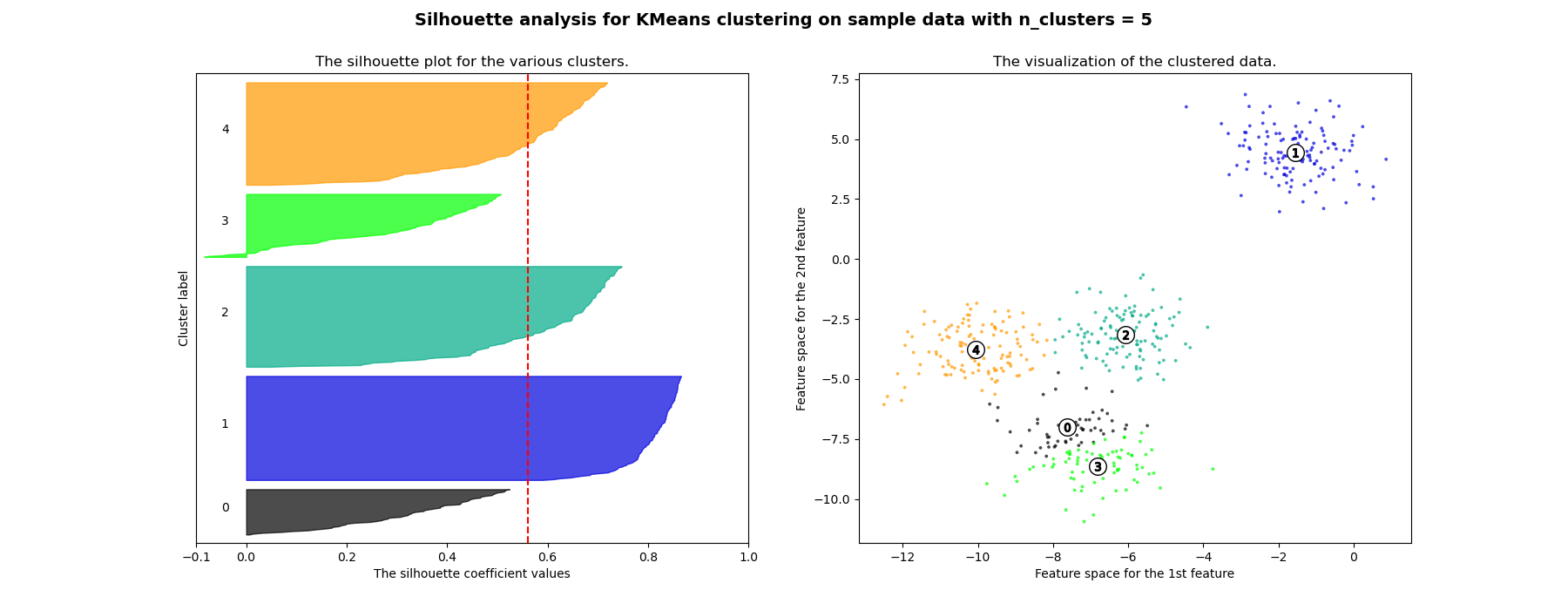
C# (CSharp) Cluster DBSCAN.Analyse - 6 examples found. These are the top rated real world C# (CSharp) examples of Cluster.DBSCAN.Analyse extracted from open source projects. You can rate examples to help us improve the quality of examples. Cluster analysis has been used to cluster stocks into sectors. Petroleum geology Cluster analysis is used to reconstruct missing bottom hole core data or missing log curves in order to evaluate reservoir properties. Physical geography The clustering of chemical properties in different sample …